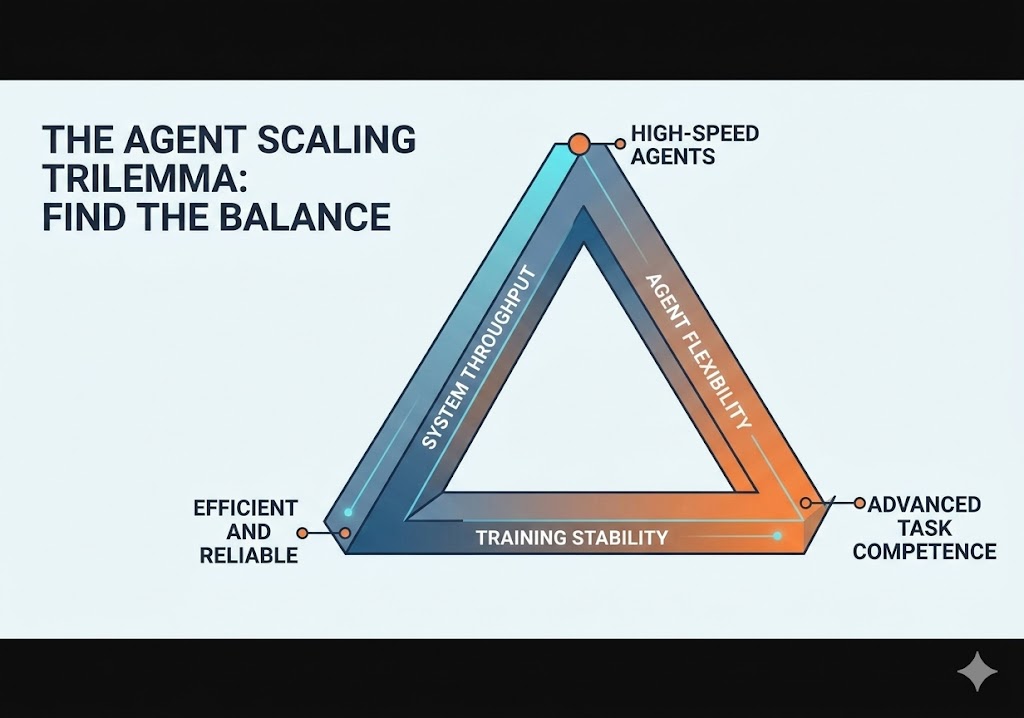
An analysis of the engineering trade-offs between throughput, stability, and agent autonomy in industrial-scale RL.
Key Takeaways
- 40x Training Speedup via Prefix Tree Merging.
- 100% GPU Utility via Windowed FIFO.
- SOTA 80.2% SWE-Bench Verified score.
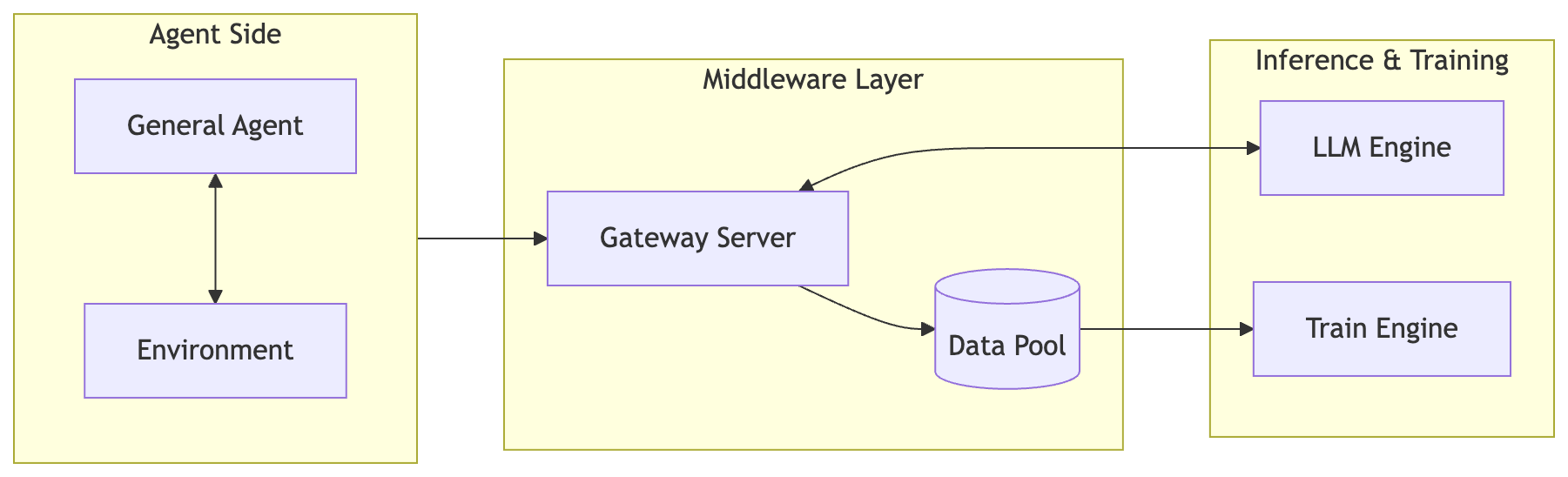
In the two weeks since the debut of MiniMax M2.5, the industry conversation has shifted from “initial hype” to “production reality.” While many were focused on the model’s SOTA scores, specifically its 80.2% on SWE-Bench Verified, the real story for engineers is Forge: the internal framework that moved Agent RL from a research experiment to an industrial-scale engine.
Scaling Reinforcement Learning (RL) for real-world agents has long been hindered by a fundamental trilemma: balancing System Throughput, Training Stability, and Agent Flexibility. MiniMax calls this the “Impossible Triangle.” Here is my analysis of how the Forge framework resolves these structural trade-offs to enable frontier intelligence at an “agent-native” price point.
The Architectural Shift: Forge vs. PPO/GRPO
Standard RL paradigms like PPO often assume a synchronous, linear environment. Forge is built for the asynchronous, complex reality of autonomous agents.
Table 1: Traditional RL vs. MiniMax Forge Framework
| Feature | Traditional RL (PPO) | MiniMax Forge Framework | Technical Impact |
|---|---|---|---|
| Scheduling | Strict FIFO (Synchronous) | Windowed FIFO (Asynchronous) | Eliminates Head-of-Line blocking; 100% GPU utility. |
| Data Logic | Linear (Redundant) | Prefix Tree Merging | 40x speedup in training throughput. |
| Context | Static Input Window | Learned Functional Action | Solves "Context Rot" in 200k token windows. |
| Optimization | Correctness only | Efficiency-Aware (CISPO) | Incentivizes Parallel Tool Calling. |
Engineering Win: 40x Efficiency with Prefix Tree Merging
In research, we often ignore data redundancy. In production, redundancy is a silent killer of TFLOPS. Agent trajectories share thousands of identical prefix tokens (system prompts, tool definitions, etc.).
The Innovation: Forge transforms the data path into a tree-structured approach. Using Magi Attention, the framework calculates the shared prefix once and only branches for unique agent completions.
Impact: This achieved a 40x training speedup, making it economically viable to train on 200k context windows, the exact capability that allows M2.5 to handle massive codebases.
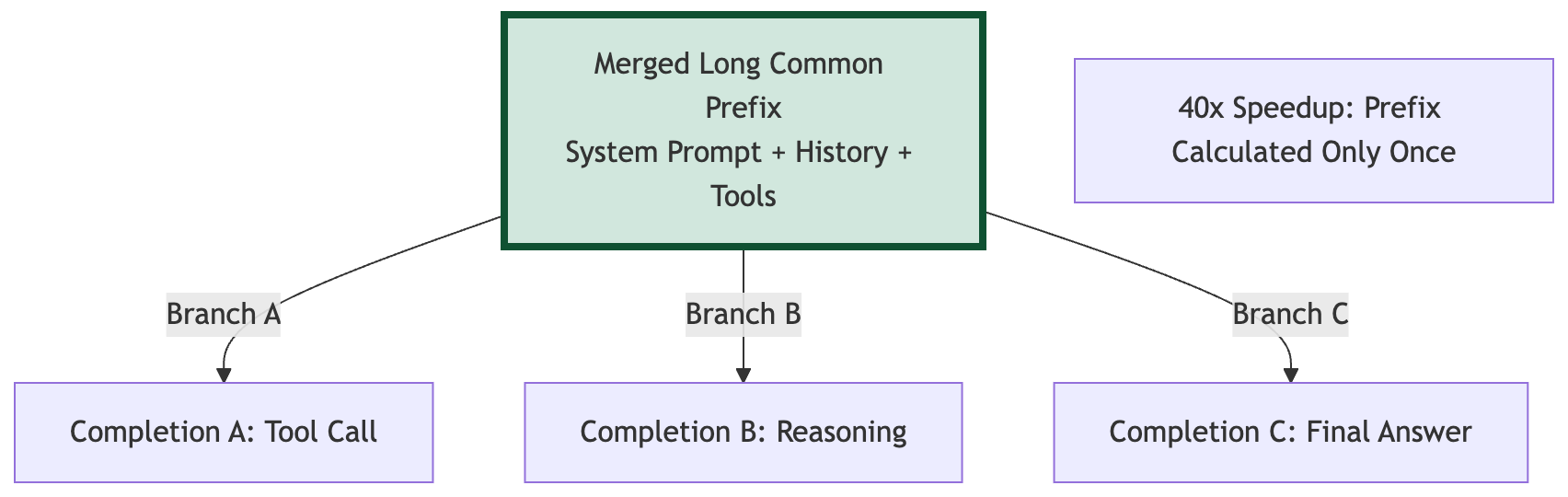
Solving Scheduling Deadlocks: Windowed FIFO
In production, one “hard” reasoning task might take hours while “easy” ones take seconds. Traditional strict scheduling causes the whole cluster to sit idle waiting for that one “straggler.”
The Solution: Forge uses a sliding visibility window. It allows for “local greedy” processing, fetching fast tasks immediately to keep GPUs busy, while forcing the scheduler to wait for stragglers before moving the window forward. This maintains a stable training distribution without wasting compute.

Deep-Dive: Stability via CISPO
The engine behind M2.5 isn’t standard PPO or GRPO; it is CISPO (Clipped Importance Sampling Policy Optimization).
While most RL algorithms clip the policy ratio to ensure stability, CISPO clips the importance sampling weights. This is a critical distinction for production agents:
- Solving the “Critical Token” Problem: In complex reasoning, high-value “thought triggers” often start with low probability. Standard clipping often “ignores” these updates to prevent spikes. CISPO preserves these gradients, allowing the model to learn complex reasoning paths more effectively.
- Efficiency as a Reward: Unlike research models that only optimize for accuracy, CISPO incorporates wall-clock execution time into the reward function. This is why M2.5 identifies parallel tool-calling opportunities, completing tasks 37% faster than previous iterations.
- Credit Assignment at 200k: CISPO uses a process reward mechanism for end-to-end monitoring. This solves the “needle in a haystack” problem of credit assignment, pinpointing exactly which step in a 1,000-turn trajectory led to the successful outcome.
Verified Results (February 26, 2026 Standing)
I waited for the data to verify these architectural claims. Two weeks post-launch, MiniMax M2.5 has validated the Forge framework on the leaderboards:
- Frontier Coding: Maintained an 80.2% on SWE-Bench Verified, rivaling Claude Opus 4.6 and GPT-5.2.
- Production Speed: Completed SWE-Bench evaluations 37% faster than previous versions through learned parallel tool usage.
- Economic Disruption: Currently the #1 used model on OpenRouter (2.45T tokens in one week), thanks to the efficiency gains that allow for $0.30 - $1.00 per hour pricing.
- Internal Utility: M2.5 now autonomously completes 30% of all tasks at MiniMax, proving it is ready for real-world employment.
Production Cost Comparison: M2.5 vs. Claude Opus 4.6
MiniMax M2.5 matches Claude Opus 4.6 in coding benchmarks and task completion speed, at roughly 1/10th the cost. The efficiency gains from Forge's Prefix Tree Merging and Windowed FIFO scheduling translate directly into pricing: $0.30 - $1.00 per hour vs. the significantly higher cost of frontier models. For teams evaluating production deployment at scale, this cost-performance ratio changes the calculus entirely.
Summary & Final Thoughts
We are entering a phase where the “secret sauce” of AI is moving from the model itself to the RL orchestration layer.
Forge proves that if you solve the engineering bottlenecks of asynchronous, long-horizon data, you can move frontier intelligence out of the research lab and into affordable, production-ready systems.
My Intent: I wrote this study to document the elegant engineering behind Prefix Redundancy and Windowed Scheduling: breakthroughs that I believe will define the next generation of industrial-scale agent training.